简介
人脸识别技术是一种生物识别技术,可以用来确认用户身份。人脸识别技术相比于传统的身份识别技术有很大的优势,主要体现在方便性上。传统的身份认证方式诸如:密码、PIN码、射频卡片、口令、指纹等,需要用户记住复杂密码或者携带身份认证钥匙。而密码、卡片均存在丢失泄露的风险,相比于人脸识别,交互性于安全性都不够高。人脸识别可以使用摄像头远距离非接触识别,相比于指纹免去了将手指按在识别区域的操作,可由摄像头自动识别。
目前人脸识别技术已经广泛应用于安全、监控、一般身份识别、考勤、走失儿童搜救等领域,对于提升身份认证的效率起到了重要的作用。而且目前还有更深入的人脸识别的研究正在进行,包括性别识别、年龄估计、心情估计等,更高水平和更高准确率的人脸识别技术对于城市安全和非接触式身份认证有巨大的作用。 人脸识别问题宏观上分为两类:人脸验证和人脸识别。人脸验证通常是做1对1的对比,判断两张图片中是否为同一人。人脸识别通常是1对多的对比,判断照片中的人是否为数据库中的某一位。
人脸识别受到多种因素影响,主要分为基础因素、内在因素和外在因素。基础因素是人脸本身就相似,人的五官、轮廓大致相同;内在因素是人的内部属性,如年龄变化、精神状态、化妆等;外部因素是成像质量的问题,比如相片的清晰程度、有无眼镜、口罩等遮挡。对于人类来说,认出一个人是很容易的事情,对于计算机而言,图片是由多维数字矩阵表示的,识别任务难度大。
最早的人脸识别是半自动人脸识别,由人工标注人脸特征点,计算机根据特征点相对位置进行人脸匹配。
在1965-1990年间的人脸识别研究主要基于人脸几何结构特征和模版匹配的方法,利用几何特征提取人眼、口、鼻等重要特征点的位置,以及眼睛等重要器官的几何直观形状作为分类特征,并据此计算特征点之间相互位置和距离,用来衡量两幅人脸图像的相似程度。
1991-1997年,基于整体的方法较多,包括主成分分析(PCA)方法、线性鉴别分析(LDA)方法等。这些方法通过寻找一组投影向量,将人脸降维,再将低维特征送入类似SVM等机器学习分类器中进行人脸分类。
1998年至2013年间,很多借助深度相机、结构光、红外相机等设备辅助人脸识别的方法出现,使得人脸识别的精度大大提高。同时还有早期的基于特征的分类方法,在人脸不同位置提取局部特征,得到的结果往往比整体方法更加具有鲁棒性。类似的有从图像块中提取HOG、LBP、SIFI、SURF特征,将各模块局部特征的向量串联,作为人脸的表示。 亦有综合方法,先使用基于特征的方法获得局部特征,再使用子空间法(比如PCA、LDA)获得低维特征,将基于整体与基于局部特征的方法。这类方法中,GaussianFace在LFW上获得了最好的精度98.52%,几乎匹敌很多后来出现的深度学习方法。
2006年后,深度学习开始得到研究人员重视,在国际期刊发表的数目越来越多。而后深度学习广泛应用于各种目标检测领域,2015年,Google团队的FaceNet在LFW数据集上得平均准确率达到了99.63%,基于深度学习的人脸识别的准确率已经高于人类本身,深度学习在人脸识别领域基本占据了统治地位。
人脸识别常见流程
绝大多数人脸识别都包含如下几个流程:人脸检测(Face Detection)、人脸对齐(Face Alignment)、人脸表示(Face Representation)和人脸匹配(Face Matching)。 如下图所示:

- 人脸检测 Face Detection
从输入的图像中检测到人脸区域,并返回人脸包围框的坐标。
- 人脸对齐(人脸配准)Face Alignment
从人脸区域中检测到人脸特征点,并以特征点为依据对人脸进行归一化操作,使人脸区域的尺度和角度一致,方便特征提取与人脸匹配。人脸对齐的最终目的是在已知的人脸方框中定位人脸的精准形状,主要分为两大类:基于优化的方法和基于回归的方法。这里基于回归树的人脸对齐算法是Vahid Kazemi 和 Josephine Sullivan于CVPR2014年发表的人脸特征点识别方法,是一种基于回归树的人脸对齐方法,这种方法通过建立一个级联残差回归树(GBDT)来使人脸从当前形状一点点回归到真实形状。
- 人脸表示Face Representation
从归一化的人脸区域中进行特征提取,得到特征向量,比如有的深度神经网络方法使用128个特征表示人脸,最理想的情况是不同的人的照片提取出的特征向量不一样,而同一人的不同照片中可以提取出相似的特征向量。
- 人脸匹配 Face Mataching
将两幅图片计算出的特征向量进行对比,获得两幅照片的相似得分。根据相似得分,得分高的可判断为同一人,得分低的判断为不同人。
人脸表示的基本思路
深度学习识别人脸的主要思路是不同的人脸由不同的特征组成。从简单的说,特征可有眼皮、鼻子、眼睛、肤色、发色,如表格所示。则5个特征可以形容25种人脸,即(特征1,特征2,特征3,特征4,特征5)可表示一种人脸,如(1,0,0,1,0)可表示一位双眼皮、低鼻梁、黑眼球、黄肤色、黑发色的人。
| 序号 | 特征 | 0 | 1 |
|---|---|---|---|
| 1 | 眼皮 | 单眼皮 | 双眼皮 |
| 2 | 鼻子 | 低鼻梁 | 高鼻梁 |
| 3 | 瞳色 | 黑色 | 棕色 |
| 4 | 肤色 | 黄色 | 白色 |
| 5 | 发色 | 黑色 | 金黄色 |
对于表格的物种特征每个特征有两种表现来说,一共可以表示的32种外貌用来做人脸识别是不够的,因此可以增加特征的数量,比如用更多的特征表示人脸,增加特征6脸型、特征7嘴唇等;同时可以增加某一特征的具体表现数量,如特征3,用0表示黑色、0.1表示黑色带点蓝色、0.2表示黄色、0.25表示棕色等等。因此当实际应用中特征数量达到1024或更高的数量级,特征值取连续的小数。扩充后,一张人脸可能表示为(0.3,2,1.5,1.75,…… ),基本可以表示无数张人脸。
在实际中,这些特征并非由人工设置的,而是由深度神经网络在训练过程中学习而来的,储存在了深度神经网络中的各节点的参数中,一个深度神经网络模型即为网络的结构和各节点的参数组成。
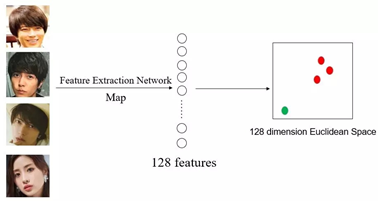
如图所示是一个128维度特征提取网络,三张山下智久的照片经过神经网络提取后的特征在128维空间中非常接近,而石原里美的照片经过神经网络处理结果就与山下智久的结果相距较远。即同一人的不同照片提取的特征在特征空间里距离相近,而不同人脸的照片在特征空间中距离较远。
工程实现样例
参照上述思路,我实现了一个简易的人脸识别程序,地址在face_identification,效果如下图所示。 本工程基本照搬了 dlib.net/dnn_face_recognition_ex.cpp,仅有些小小的改变,dlib的方法中使用了ResNet34用作人脸识别网络,该残差网络的详细内容参照何凯明等人的工作Deep Residual Network at 2015。

设计思路
- 界面:本软件使用Qt作为界面软件设计,为了快速编码,使用了Qt Example中的Camera样例工程,将人脸识别内嵌在其中。重写了画布,可以按照想要的时间间隔调用人脸识别代码。
- 多线程:根据相机分辨率的不同,一次人脸识别流程耗时在0.2-0.4s不等,如果使用单线程开发,会导致识别人脸的时候相机画面卡住。因此使用了Qt的多线程支持,将人脸识别流程放在了其他线程,UI线程与人脸识别线程中采用Qt的信号与槽机制通信。
- 人脸检测:使用dlib中的frontal_face_detector正面人脸检测器,检测画面中的人脸区域。
- 人脸Landmark标记:使用dlib的shape_predictor_5_face_landmarks.dat五个特征点检测模型,检测眼睛鼻子嘴角共五个特征点,用于调整图像尺寸、人脸角度,归一化为 150x150分辨率,供特征提取网络使用。
- 特征提取:使用ResNet34网络稍作调整,网络输入150x150图像,输出128个特征值。
- 识别-建立数据库:利用csv文件存贮已知人物身份列表(包括一张身份图片),先将作为原始数据的图像经过特征提取,生成尺寸为[图像数量,128]的矩阵。利用FLANN为该数据建立索引数。
- 识别-查找数据库:相机识别到的人脸经过特征提取后得到的128个特征向量在FLANN索引中寻找最近点,并计算与最近点之间的距离,如果距离在阈值范围内,则判定为同一用户。
环境依赖
工程实际使用了Qt和一些主要依赖库,但为了工程管理方便,我直接在工程的libs.pri中设置了对于外部库的引用,主要使用了如下外部库。
Dlib 19.17
opencv 3.4
flann 1.9.1
也就是说,如果你需要在我的代码基础上进行修改,则需要首先配置好这些库,然后修改libs.pri文件中对于这些库的链接地址,然后才可以顺利编译成功。
更多
如果对于该程序设计还有更多的疑问,欢迎前往该工程的Issues板块提问,我会尽快解答疑问。
Reference
- face_identification
- Dlib 19.17
- opencv 3.4.5
- Qt 5.12 Mingw 730 x64
- qtcsv 1.5.0
- FLANN 1.9.1
- Kazemi V , Sullivan J . One Millisecond Face Alignment with an Ensemble of Regression Trees[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 2014.
- Schroff F , Kalenichenko D , Philbin J . FaceNet: A Unified Embedding for Face Recognition and Clustering[J]. 2015.
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
